The magic of synthetic data: How nonexistent fingerprints help identify real criminals
Contributors

Igor Jánoš
Image data synthesis
lead at Innovatrics
To train a viable AI model, you need data. Lots of it. But what do you do if there just isn’t enough? Simple: you make some up. Or, to put it in fancier terms, you “generate synthetic data”.
Igor Jánoš, image data synthesis lead at Innovatrics, explains why the world is in need of more data than we currently generate, and how creating synthetic data can not only help to catch criminals but also to safely train the self-driving cars of the future.
What is synthetic data and why is it useful?
Synthetic data is an artificially generated dataset that can be modelled to look like a real dataset or be deliberately skewed to exaggerate an important aspect.
Let’s say you are developing an AI to identify problematic roads in a city. You spend an enormous amount of money and time recording hundreds of hours of footage from thousands of roads, and use that to train your AI to find problematic aspects of roads. However, that takes a lot of time, effort and expense.
For the computer, each road is just a set of numbers anyway: one might represent the position of the road, another might represent its length, the time of day or the number of cars driving through it. So why spend your time recording, when you can just randomly scramble the variables and generate thousands of possible road variations on the spot?

As long as you make sure your artificial roads have parameters similar to real-world roads (similar lengths, traffic density, etc.) and similar distributions (i.e. every city has a myriad of smaller streets and far fewer main highways, and this should be similarly represented in the data), AI will not see the difference.
That is one of the biggest upsides of synthetic data – it’s cheap, fast and, as we will see, it can be a good way to get around personal data restrictions.
Of course, there are also downsides. Synthetic data is good for “filling in the curve” of the standard distribution, but will seldom increase the complexity, introduce new edge cases, or reflect any real-world outliers. And most importantly, it’s only ever as good as the real-world data you feed in.
One can never have enough fingerprints
Did you know that fingerprints are a scarce resource? When it comes to a criminal investigation, certain types of fingerprints are rare – and therefore so valuable that, for Igor Jánoš, it’s worth creating and training AI models with the sole purpose of creating synthetic fingerprints.
The most readily available types of fingerprints are scanned. Pushing your whole finger on a scanner surface, you take a clean black-and-white scan of your full fingerprint pattern. This makes it very easy to identify the distinctive features of the fingerprint – called “minutiae points” – such as ridge endings, bifurcations or spurs.
“With databases full of millions of clear fingerprints, all similarly sized and clearly labelled, it’s possible to easily train a neural network to search for patterns. In these cases it can recognise and identify your print in a fraction of a second by comparing it to the fingerprints in the database,” explained Igor Jánoš.

However, in criminal investigations things are not that easy. You are mostly dealing with latent fingerprints – damaged or distorted remnants of an original fingerprint, which are also only photographed, not scanned. That means each print is likely to have a different size and rotation (as the photos are taken when at the crime scene), to have been shot from a different angle, and have different backgrounds or lens relics.
In addition, if this lack of homogeneous data is not enough, there is also a problem with data privacy. “The fingerprints are still protected under GDPR as personal data, and of course no police department will open their archives for you just to train your algorithm,” explains Jánoš.
There is just one certified, publicly accessible dataset of 10,000 pictures of latent fingerprints. And it only contains prints of 250 distinct individuals.

So, between the lack of material from which to train, and the lack of variety in the data that does exist, is there a way to improve the identification of fingerprints “in the wild” via an algorithm? Yes, by generating synthetic ones.
Generating synthetic fingerprints? It’s harder than you think
You will almost certainly have heard of image generators like DALL-E or Stable Diffusion. Well, what if, instead of generating random images, you trained the generator to create … synthetic fingerprints?
It’s hard, but it is possible.
There is plenty of training data from scanned fingerprint images, but the way in which image generation works makes it hard to generate pictures without gradual colour transitions. And fingerprints are the definition of having no transition – they’re just clear-cut black-and-white lines.
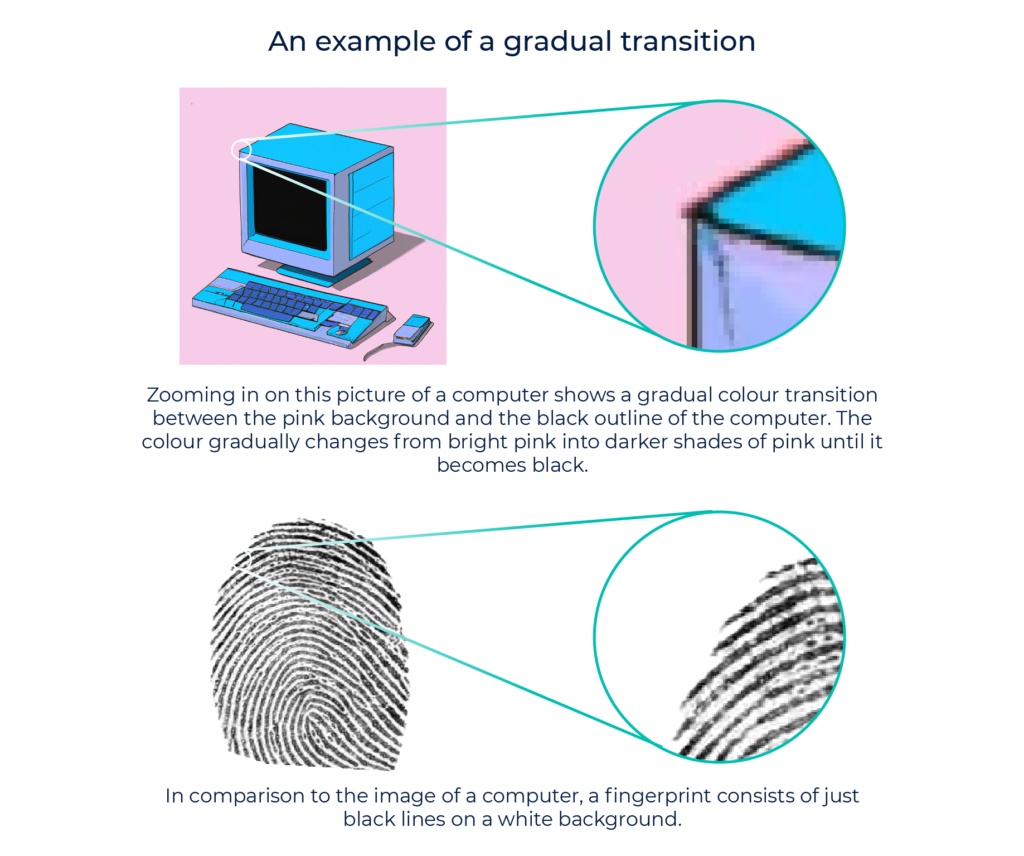
Learn more about the pitfalls of fingerprint generating from Igor Jánoš’s talk at the Better AI Meetup
However, after hours of training, you can get a model to generate oval shaped fingerprints with distinct minutiae points – structures, bifurcations and spurs. And you are half way there!

Now comes the other difficult part – making the fingerprints “latent”, in other words, damaged or incomplete. This is done by introducing the real, very limited set of latent fingerprints from an existing database. You need to carefully nudge the algorithm in the right direction by building layer upon layer of distortion – clippings, smudges, deleting parts of the image – all while keeping the important minutiae points intact.
Igor Jánoš concludes: “The result, after days of training and weeks of research time, is a highly realistic, but importantly ‘not’ real, latent fingerprint.”
Investigators around the globe use it right now
ABIS (automated biometric identification system) by Innovatrics is already deployed in one of the largest biometric criminal investigation systems in the world.
Used to identify fingerprints, faces or irises, it’s able to find matches from millions of database entries in a fraction of a second.
What to do with synthetic data? Teach your neural network
Once you have generated high-quality synthetic data, you can use it to train other networks that do the actual work you need. This might be the recognition and pairing of latent fingerprints with their scanned counterparts, as in the research of Igor Jánoš, or matching mugshots from police databases with the partial face images from CCTV cameras.
Outside of the justice system, synthetic data is used daily. For example, it’s used to improve the statistical models of insurance companies, or to help identify fraudulent payments by modelling customer behaviours for banks. It even makes sensitive health-related data publicly accessible by generating synthetic data modelled on real patients without breaching their confidentiality.
One of the more ”futuristic” uses of synthetic data is the training of self-driving cars. Instead of allowing self-driving vehicles to train on the road, the majority of the training is done on vast 3D-simulations of roads, intersections and entire cities. A neural network is let loose inside these simulated situations and can get years of driving experience in a matter of weeks or months.
The data of the future is synthetic
In a world where machine learning is used in more applications every minute, synthetic data is quickly rising to prominence. It will improve big models and allow us to create new applications we’d previously never thought possible. What is now a tiny market of $169 million is forecasted to grow to $3.5 billion by 2031.
And it has the potential to make our world not just better, but safer for all.
AUTHOR: Andrej Kras

